
开云体育 GRPO遭逢瓶颈? G²RPO-A让自适合辅导为小模子推理才智「开外挂」


大模子期间的「真金不怕火金术师」们,大约皆曾面对一个共同的困扰:当咱们试图将 DeepSeek-R1、OpenAI-o1 那种惊艳的推理才智迁徙到小领域话语模子(SLMs)时,驱散却老是差强东谈主意。现存的强化学习要领如 GRPO 在 7B+ 的大模子上驱散权贵,但一朝诳骗到 1.7B 致使更小参数的模子上,性能普及就一丁点儿。
针对小模子在强化学习中的推理逆境,香港汉文大学(深圳)T-Lab 唐晓莹教会携课题组博士毕业生郭永新、邓文博提倡了全新算法 G²RPO-A(Guided Group Relative Policy Optimization with Adaptive Guidance)。已被 ACL 2026 主会议(Main Conference)继承。
该要领通过在 roll-out 经由中注入高质地念念维轨迹,并左证教授现象动态颐养辅导强度,有用缓解小模子面对的奖励稀零问题。在 Llama、Qwen、DeepSeek 等多个主流模子家眷上的执行标明,G²RPO-A 在数学推理和代码生成任务上权贵优于 vanilla GRPO,其中 Qwen3-1.7B 在 MATH500 上从 50.96 普及到 67.21,HumanEval 上从 46.08 普及到 75.93。

论文地址:G²RPO-A: Guided Group Relative Policy Optimization with Adaptive Guidance
论文洽商:https://arxiv.org/abs/2508.13023
代码仓库:https://github.com/T-Lab-CUHKSZ/G2RPO-A
单元:♠ 香港汉文大学(深圳) ♡ 淘天集团(郭永新为香港汉文大学(深圳)T-Lab毕业博士生) ♣ 西湖大学
「咱们用 GRPO 教授了 Qwen3-1.7B,驱散高奖励候选遥远太少,模子很难踏实学到有用的推理政策……」
一个灵魂拷问随之而来:难谈小模子注定与高档推理才智无缘吗?
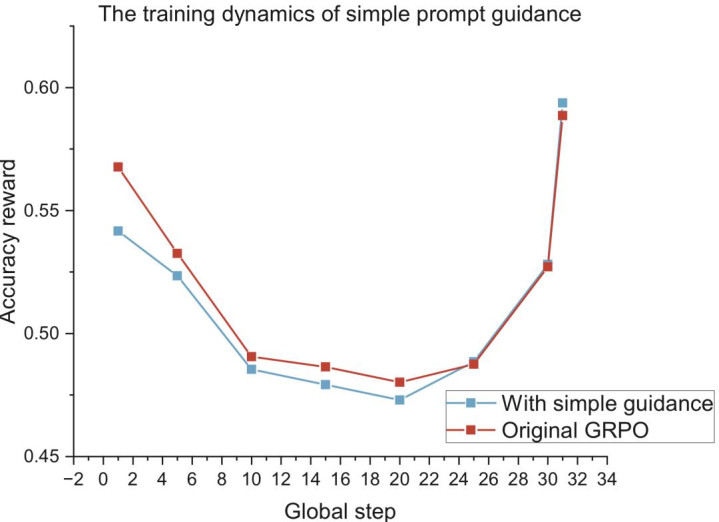
图 1:Naive Guidance 的逆境。使用 Qwen2.5-Math-7B 在 s1K-1.1 数据集上教授,浅薄的固定长度辅导在早期教授阶段有陡然普及,但很快与 vanilla GRPO 无异。
一、小模子的「推理瓶颈」到底卡在哪?
刻下,尽管 GRPO 等强化学习算法在大模子上取得了广泛收效,但在小领域话语模子(SLMs)上却面对严峻挑战。盘考团队通过潜入分析发现,问题的中枢在于「稀零奖励」逆境:
由于 SLMs 自身才智有限,面对复杂推理任务时,它们很难生成高质地的念念考链,导致大部分 roll-out 皆无法取得正向奖励。如下图所示,Qwen3-1.7B 在代码任务上的奖励分散极其稀零:
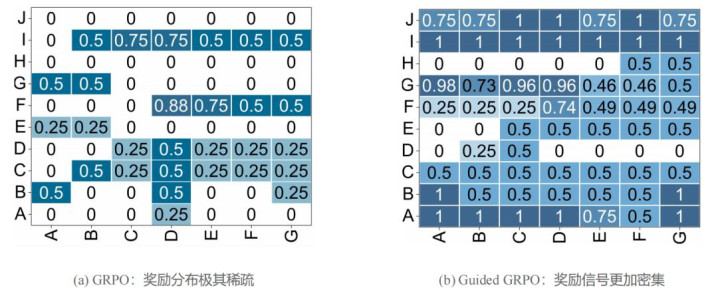
图 2:Qwen3-1.7B 在代码任务上的奖励热力求对比。引入 guidance 后,模子更容易采样到高奖励候选,奖励信号权贵变得更密集。
盘考团队形象地将其比作「生手司机开手动挡」:无论引擎(模子)奈何勤勉,缺少正确的指令(辅导)依然难以完成复杂的驾驶(推理)操作。
二、G²RPO-A 核默算法架构
为了缓解小模子在 RLVR 中的先天颓势,G²RPO-A 并不是浅薄地把措施谜底喂给模子,而是在 roll-out 的部分轨迹中注入高质地 thinking trajectory,并左证教授现象动态颐养 guidance 强度。
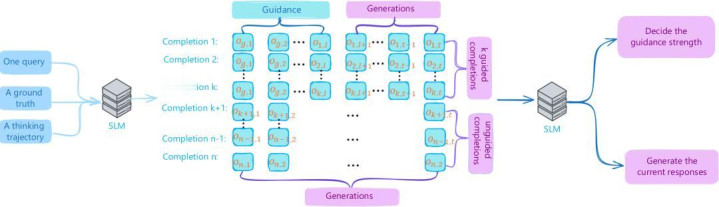
图 3:G²RPO-A 的全体框架。每一步教授皆会将 roll-out 分红 guided 和 unguided 两组,再左证刻下奖励与历史奖励的比值动态颐养后续 guidance length。
G²RPO-A 的中枢革命包含两个关节组件:
辅导机制(Guidance Mechanism):在模子生成 roll-out 的经由中,注入部分高质地的念念维轨迹看成指令,使 SLM 朝向生成更高质地候选谜底的主见发展。

三、关节发现:
为什么浅薄辅导行欠亨?
盘考团队率先考据了 naive guidance 的驱散,发现浅薄的固定长度辅导驱散有限。更关节的是,在基于 Math-220K 子集的教授动态分析里,这种「看起来更容易拿到奖励」的作念法并莫得真确带来更健康的优化信号:
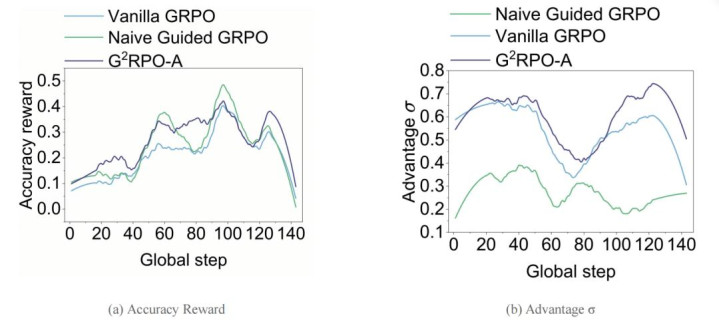
图 4:Naive Guided GRPO 的陷坑。论文在基于 Math-220K 子集的教授动态中发现,naive guidance 诚然能陡然举高 reward,但其 advantage 措施差极低,严重报复了 SLM 的教授遵守。
换句话说,naive guidance 的问题不在于「完全没匡助」,而在于它仅仅让模子更容易采到一些高奖励候选,却莫得同步保住饱和有分手度的 advantage 信号;驱散即是奖励看似变好,教授遵守却莫得真确普及。
四、主执行驱散:
数学和代码上到底涨了些许?
论文作念了大宗成立执行,率先,开云体育最值得展示的其实是主执行驱散:在协调教授建立下,径直和 Base、vanilla GRPO、SFT 对比,望望 G²RPO-A 是否果然能把小模子带起来。
成立分析自己给出的中枢论断不错先记一句:代码任务经常需要更高 guidance ratio,小模子也经常比大模子更依赖 guidance。这亦然作家临了转向「自适合」而不是「固定超参」的径直动机。
先看数学推理主执行。下表来自论文主表,展示了不同 Qwen3 基座在多个数学 benchmark 上的驱散:
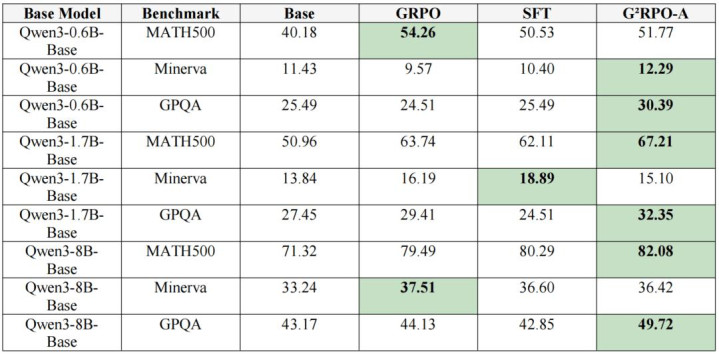
表 1:论文主执行中的数学 benchmark 驱散,单元为准确率(%)。
要是只看最有代表性的几组驱散,普及是很直不雅的:Qwen3-1.7B-Base 在 MATH500 上从 50.96 普及到 67.21,在 GPQA 上从 27.45 普及到 32.35;Qwen3-8B-Base 在 MATH500 上也从 71.32 普及到 82.08。论文还补充了更强数学建立下的 AIME 驱散,其中 Qwen3-1.7B 在 AIME24/AIME25 上分别达到 63.33 和 53.33,高于对应的 GRPO 驱散 56.67 和 50.00。
再看代码主执行。这里的趋势也很有兴致:G²RPO-A 并不是「每一个单项皆十足碾压」,但全体上在多数 benchmark 上拿到了最优,尤其对小模子的拉升颠倒通晓。

表 2:论文主执行中的代码 benchmark 驱散,单元为准确率(%)。
具体来说,Qwen3-0.6B 在 HumanEval 上从 32.32 普及到 44.96,LiveCodeBench 上从 17.07 普及到 23.14;Qwen3-1.7B 在 HumanEval 上从 46.08 普及到 75.93。需要真实诠释的是,Qwen3-1.7B 在 LiveCodeBench 上是 SFT 略高,但论文独特给出的 Code-Avg 对比中,G²RPO-A 仍以 63.95 高于 GRPO 的 60.40 和 Clip-Higher 的 60.19。
五、自适合政策的中枢念念想
G²RPO-A 的关节不在于「永远加更多 guidance」,而在于左证最近几个教授 step 的奖励变化自动调 guidance length。论文里的更新律例更接近底下这个体式:
辅导长度自适合更新律例:
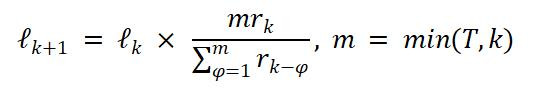
其中,m=min(T,k),ℓₖ 为第 k 步的 guidance length,rₖ 为刻下奖励,T 为历史窗口。奖励走高则裁减 guidance,奖励走弱则拉长 guidance。
直不雅通晓:若最近奖励抓续飞腾,则冉冉裁减 guidance,让模子自主完成更多推理;若奖励下落,则符合拉长 guidance,训斥教授难度。
直观上,要是最近奖励抓续飞腾,就冉冉裁减 guidance,让模子我方完成更多推理;要是最近奖励下落,就符合拉长 guidance,先把教授难度降下来。这比东谈主为预设一个固定 schedule 更逼近论文真确想抒发的「adaptive」。
归来与瞻望
这项责任的价值,不仅仅提倡了一个新 trick,而是把「小模子为什么在 RLVR 里吃不到有用奖励」这件事分析得更明晰:问题不仅仅模子小,更在于奖励稀零、advantage 方差信号不及,何况辅导强度还会随教授经由变化。
作家也坦言,刻下要领仍有两个通晓界限:一是考据主要辘集在数学和代码任务,跨模态等场景还有待测验;二是 guidance ratio α 仍依赖教养搜索,离真确完全自适合还有一步。
论文和名堂仓库皆照旧公开开云体育,这项责任为小领域话语模子在 RLVR 场景中的教授蓄意提供了一个很有价值的主见。
亚博体育中国官网注册登录



 备案号:
备案号: